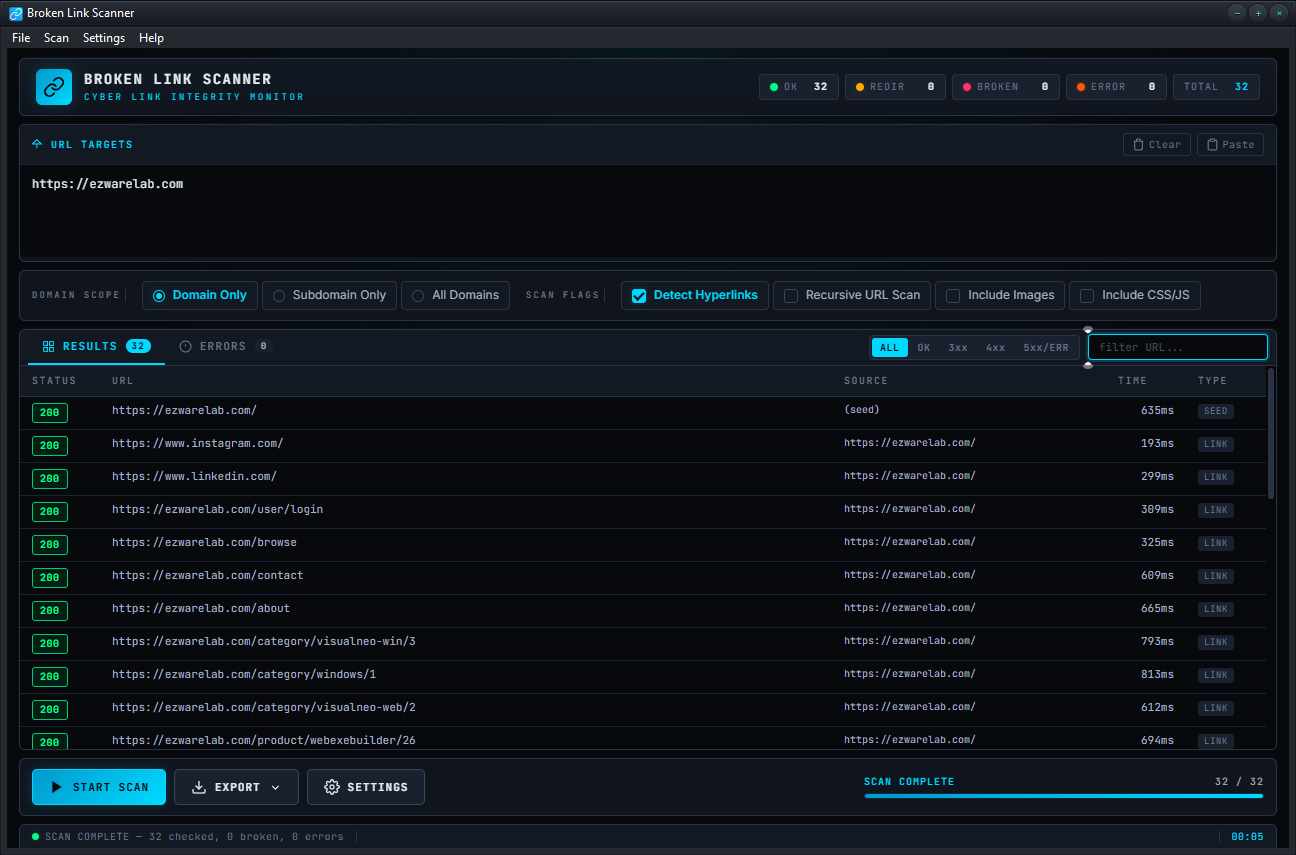
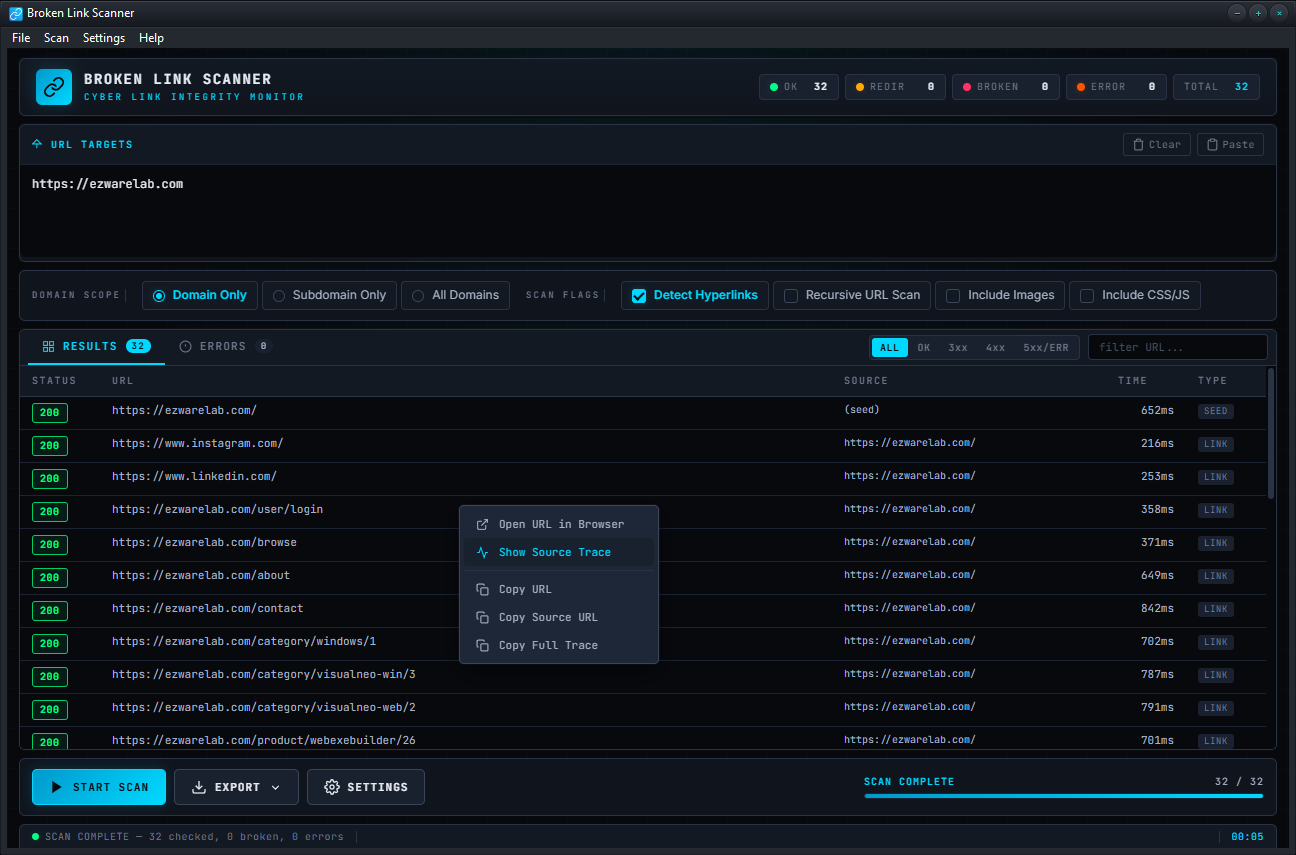
Broken Link Scanner crawls your website, follows every link, image and resource, and reports exactly which ones are broken, where they live, and what's wrong with them. Real-time results,full status codes, source-chain tracing, and one-click export tto Excel, CSV, JSON or text.
* Stop losing visitors to dead links. Scan, find, fix.
Real status codes, not just "ok / broken". Distinguish 404 from 403 from 500 from a redirect chain that ends in 200.
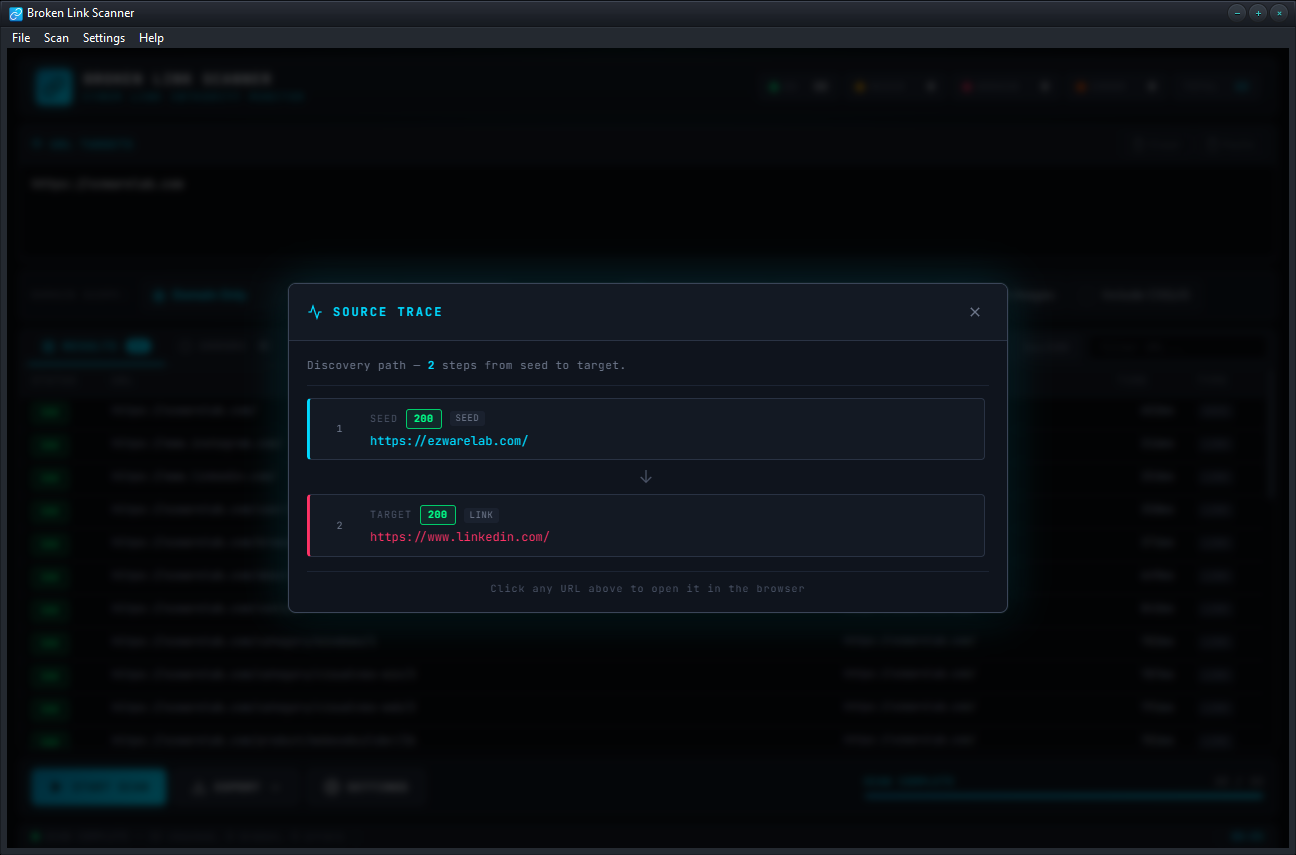
Right-click any broken link to see the complete path of pages that led to it. No more hunting through HTML to find where a dead URL is referenced.
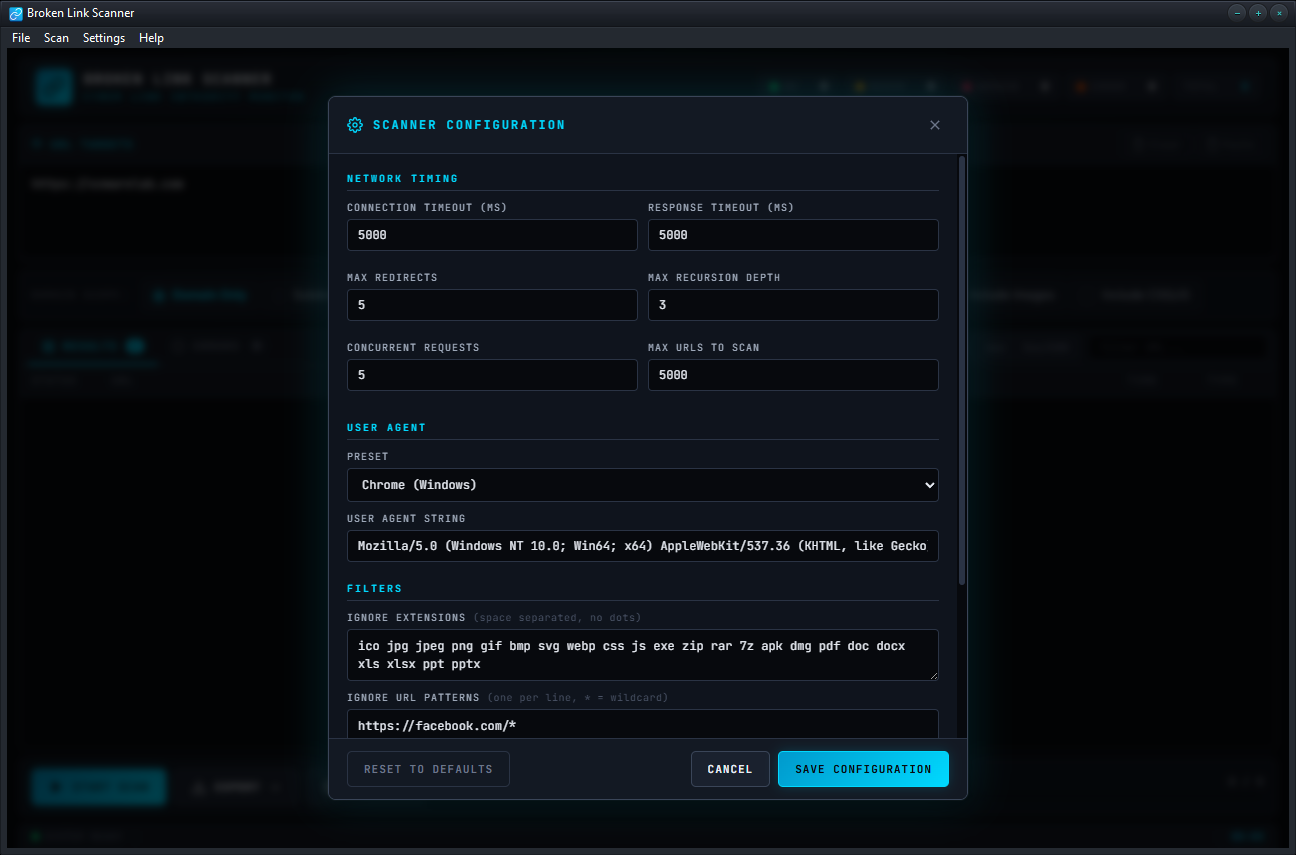
Optional depth-limited recursion follows hyperlinks to find every page reachable from your seed URLs. Domain scoping keeps the scan focused on your site.
Up to 20 concurrent connections. Scan thousands of URLs in minutes, not hours.
Skip the noise -- ignore image extensions, exclude admin URLs, filter results by status code or text, all live.
XLS (opens in Excel), CSV, JSON, or plain text. Pick the format that fits your workflow.
Load URLs from a saved HTML file, a JSON document (any structure, any depth), or a plain text list.
Designed for long sessions. Dark, focused, monospace, with real-time status indicators and a glowing cyan accent that signals exactly what's happening at all times.
Watch results stream in as URLs are checked. See the current URL being verified, the elapsed time, and a progress bar that updates as the recursive scan discovers more links.
Automatic PowerShell fallback for restricted environments where standard browser fetch is blocked. Scans complete even when other tools fail.
Runs entirely on your machine. Your URLs and scan results never leave your computer.
Platform: Windows 10 / 11 (64-bit)
Footprint: Single executable
Network: HTTPS / HTTP, TLS 1.2 and 1.3
HTTP methods: HEAD (default, fastest) or GET, with auto-fallback
User agent: Configurable, six built-in browser presets
Concurrency: 1 to 20 parallel connections
Recursion: Depth-limited (1 to 20 hops), domain-scoped
Capacity: Up to 100,000 URLs per scan (registered)
Export formats: XLS, CSV, JSON, TXT
Engine: Microsoft WebView2 with PowerShell fallback
Q: How is this different from online link checkers?
A: It runs on your computer, scans as fast as your network allows, never throttles you, never sends your URLs to a third party, and works on private staging and intranet sites that online tools can't even reach
Q: Will it crash my server?
A: No. Concurrency is fully adjustable -- drop it to 2 or 3 if you're scanning a fragile or rate-limited target.
Q: Does it follow JavaScript-rendered links?
A: No. It checks the raw HTML source, like Google's crawler. This is the right behavior for SEO-focused link auditing.
Q: Can I scan password-protected sites?
A: Set a custom User Agent and it works on any site that doesn't require interactive login. For login-required pages, use a session-aware tool.
Q: What happens to my data?
A: It stays on your computer. Settings save locally, results stay in memory until you export them.
-----------------------------
1. Paste one or more URLs into the URL TARGETS box at the top.
One URL per line. The "https://" prefix is added automatically
if you leave it off.
2. Choose your domain scope:
- Domain Only Scan within the same root domain only
- Subdomain Only Scan within the exact subdomain only
- All Domains Follow links anywhere (default)
3. Pick what to check:
[x] Detect Hyperlinks on the page
[x] Include Images
[ ] Recursive URL Scan Follow links to find more pages
[ ] Include CSS/JS
--------------------------
The unregistered version is fully functional with two limits:
- Each scan is capped at 100 URLs total
- Exports include a "Register" notice line/row
Registering removes both. To register:
1. Click the UNREGISTERED indicator at the bottom right (or open Help -> About from the menu)
2. Click "Register now"
3. Enter your registration details
4. The app updates immediately -- no restart needed
v1.2.0.0 - Portability updates
v1.1.0.0 - Dark and Light theme mode toggle added with session persistence
v1.0.0.0 - Initial Release
Your review goes here
1.20
Jun 13, 2026 - 01:17 AM
May 04, 2026 - 01:44 AM
Windows



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
No Reviews